If you've deployed AI agents into live business environments, you know the feeling. Leadership pushes for AI-forward operations. An agent gets dropped into a workflow. And suddenly your team is cleaning up after it.
The process wasn't perfect before, but at least it hit its SLAs. Now you're fielding exceptions that used to be handled automatically. You're debugging failures that make no sense. You're explaining to stakeholders why the "intelligent" system missed something obvious.
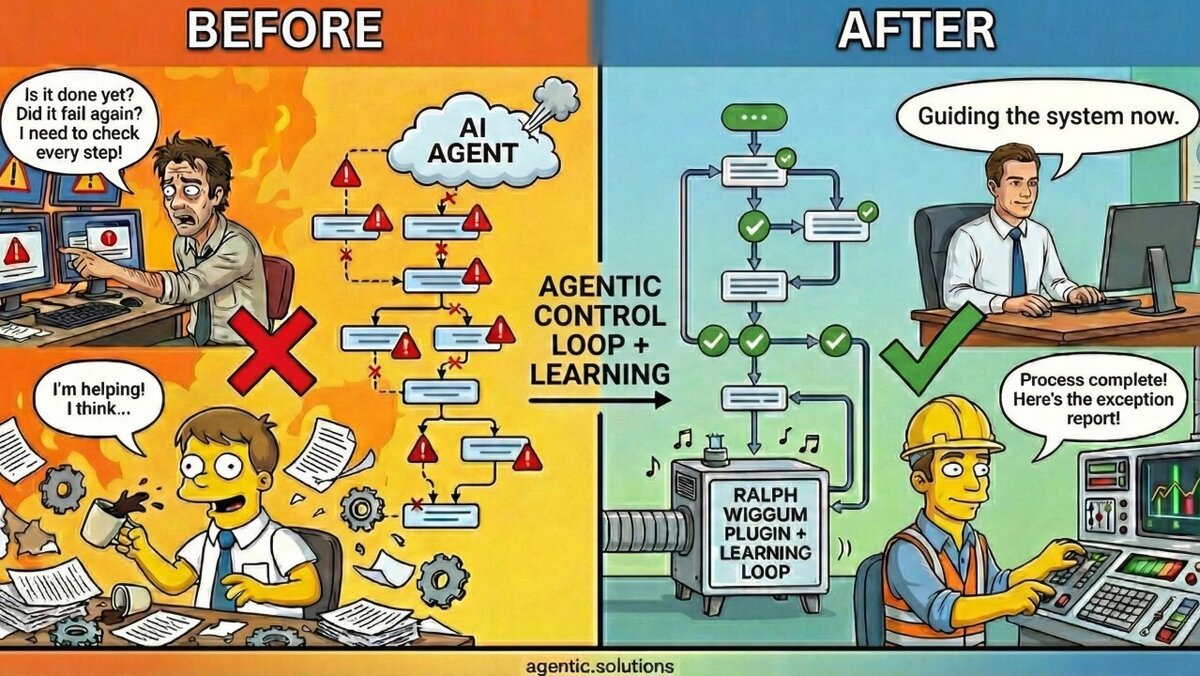
Your team starts calling the agent "the intern." Smart, but unreliable. Can't be left alone. Declares victory before the job is actually done.
There's a Name for This Behavior
In Claude Code's official plugin marketplace, there's a plugin called Ralph Wiggum. If you know The Simpsons, you know the character: the cheerfully oblivious son of the town's police chief, famous for lines like "Me fail English? That's unpossible!"
Ralph wanders into situations he doesn't fully understand, fails constantly, doesn't notice, and keeps going. Occasionally, he stumbles into something genuinely useful.
Sound familiar?
The plugin is named after him because it fixes what he represents: agents that give up too early or declare "done" without actually completing everything. It prevents the AI from stopping until it returns a specific completion phrase, and passes all failure data into the next round so the agent has full context on what went wrong.
We've built on this pattern by adding a critical learning loop. The system doesn't just retry within a session. It captures what worked and what failed across sessions, so future runs start smarter. Your processes optimize over time.
This pattern is critical to implementing robust business processes today, from coding to warehouse fulfillment to customer profile enrichment.
The Problem Smart Models Don't Solve
Intelligence doesn't guarantee completion. You can have the smartest model available, and it will still:
- Stop prematurely when it thinks it's done (but isn't)
- Miss edge cases on the first pass
- Need multiple iterations to converge on a robust solution
The model's capability isn't the bottleneck. Process completion is.
Why Agents Quit Early
Agents aren't lazy. They're optimized wrong for business processes.
They're trained to be helpful, not always persistent. The model satisfies the immediate prompt and moves on. "I've done what you asked" feels like done, even when the actual workflow has five more steps.
They lack visibility into downstream requirements. The agent doesn't know if its output actually worked in the next system, passed validation, or met the SLA. It can't see the consequences of stopping.
"Good enough" feels like done. Without explicit completion criteria, agents pattern-match to what looks like a reasonable stopping point. 80% complete looks a lot like 100% complete from the inside.
No built-in persistence mechanism. Each interaction is stateless. There's no native loop that says "keep going until X is true." The agent does a pass, declares victory, and waits for the next prompt.
This is why smart models still produce incomplete work. The intelligence is there. The drive to finish isn't.
How the Pattern Works
The plugin implements what developer Geoffrey Huntley calls "a bash loop": you set success criteria and a completion phrase. When the agent tries to exit, the plugin intercepts it. Unless the agent returns the exact completion phrase, it can't stop. Each round gets full context on what went wrong and what was tried.
The philosophy: "It's better to fail predictably than succeed unpredictably."
This solves the immediate problem: agents that give up or declare victory prematurely. But for business-critical processes, you need more than retry logic. You need the system to get smarter over time.
The Operational Shift: Hovering → Management by Exception
We all know the hovering manager. Standing behind your desk. Asking for updates every fifteen minutes. Reviewing every draft before it's ready.
That's exactly how most people work with AI agents today.
The hovering model:
- Watch every step
- Approve every action
- Intervene constantly
- Your time is consumed by supervision, not judgment
Management by exception:
- Define success criteria upfront
- Let the system iterate toward them
- Handle only the exceptions that require your expertise
Processes in the real world break. Edge cases surface constantly when agentic processes hit live environments. You either hover, or you apply a pattern like Ralph Wiggum where the system uses compute to explore the problem space until it finds a path forward.
Business Process Example: Quarterly Vendor Contract Review
The hovering approach: Feed contracts to the AI one by one. Review each summary. Manually track completion. Spend 3 days on a process that should take hours.
Systematic completion + exception handling:
Process all Q1 vendor contracts from /contracts/q1-review/:
SUCCESS CRITERIA:
- Every contract has: renewal date extracted, non-standard terms flagged,
obligation summary, risk rating (1-5)
- Confidence score >90% on all extractions
- Exception report generated for contracts requiring human review
COMPLETION CONDITIONS:
- All contracts processed OR
- After 30 iterations: generate status report with blocking issues documented
OUTPUT: Structured JSON + exception report + audit trailYou run this, walk away, and come back to either a completed review with full audit trail, or an exception report telling you exactly which contracts need human judgment and why.
Other applications:
- Support ticket triage: Process queue, categorize, route, draft responses. Alert humans only for escalations.
- Compliance scanning: Review materials, flag violations, escalate only items above risk threshold.
- Data reconciliation: Match transactions across systems, iterate until resolved or exception-logged.
- RFP response drafting: Pull from knowledge base, self-review against requirements, iterate until coverage complete.
The Danger Zone
Smart models can create a dangerous illusion.
When an agent succeeds 50% of the time, humans stay engaged. They keep their hands on the wheel.
The danger zone is 80-99%. Success rates climb. Humans disengage. Autopilot kicks in. But "most cases" isn't good enough for business-critical systems. You need the nines: 99%, 99.9%, or higher.
A 95% success rate means 1 in 20 processes fail silently while no one's watching.
Ralph Wiggum bridges this gap. Instead of hoping the agent completes, the system enforces completion. Instead of silent failures, you get documented exceptions.
Each business decides how many nines their processes require, but without systematic completion, you're stuck where humans have disengaged but the system isn't reliable enough to deserve that trust.
From Pattern to Operational Advantage
The official plugin solves completion. But completion alone doesn't get you to the nines.
That's why we've added long-term process learning on top of the Ralph Wiggum pattern. Every iteration captures what works. Every failure becomes training data for the next run. The system gets smarter about your specific processes, edge cases, and environment—not just within a session, but across sessions.
This is the difference between deploying an agent and deploying an operational system. One gives you demos. The other gives you reliable processes that reach the nines and keep improving.
The Takeaway
People call agents "interns" for a reason: smart, but unreliable without supervision. The capabilities are there, but execution is inconsistent.
The Ralph Wiggum pattern fixes the completion problem. Add a learning loop, and the system doesn't just complete—it improves.
With persistence, all the reasoning and intelligence in the model gets connected like a drivetrain. The process gains traction. Instead of spinning out on the first obstacle, it works through the problem space, learns from failures, and finds a path forward.
The intelligence was always there. This pattern lets it actually land.
Your job shifts from hovering to:
- Defining success criteria precisely
- Enabling systematic completion with learning
- Handling the exceptions that surface
That's management by exception. That's how agentic processes become operational.